In this article, we'll compare the HideMYAI tool with other services and methods that people use to make AI content more humanlike.
For this comparison, we'll use content generated on ChatGPT (free), using the prompt: "Write me one PhD level paragraph about the domestication of dogs".
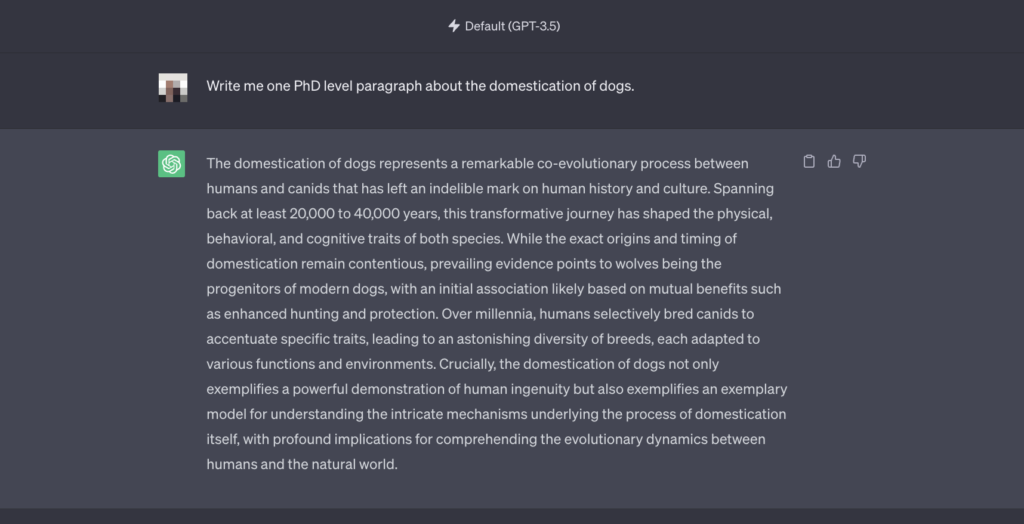

This is the output of roughly ~150 words. It's good content, but it's apparent that it's written by ChatGPT, even by an untrained eye. Once passed through a leading detector tool, it's even more apparent with a 100% AI score.
After passing it though the HideMyAI tool, the reworded content now scores a 98% originality score (with no human editing). The wordcount has also increased slightly.
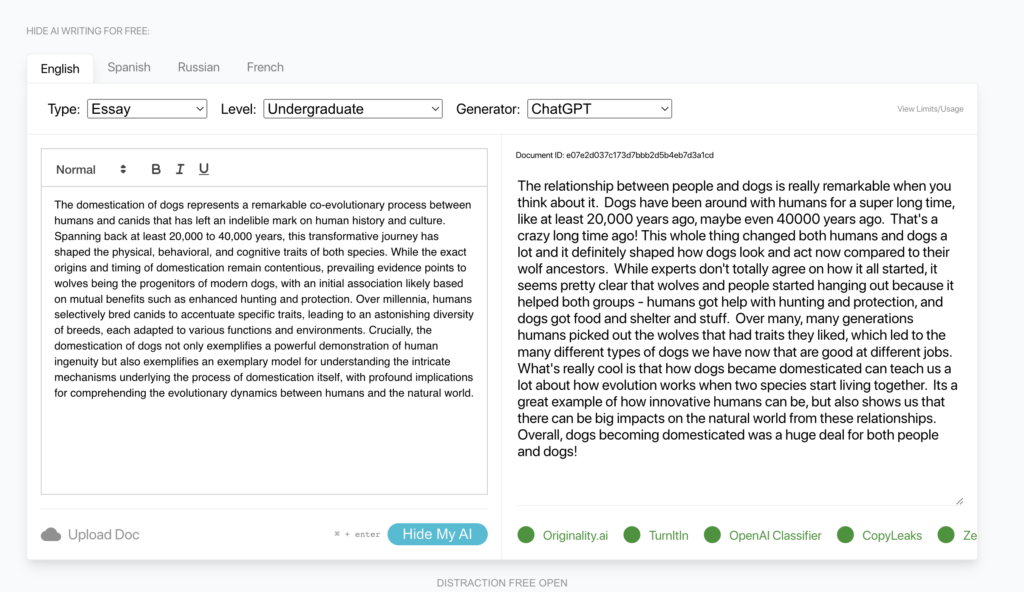

Many people try and tune the ChatGPT output to sound more human-like by using prompting techniques. For example, here's how I got the following output: "Write it like a human would, DO NOT SOUND like output from a LLM. Be unique, include grammar errors, and humanize your output. It should be undetectable by AI detector tools."
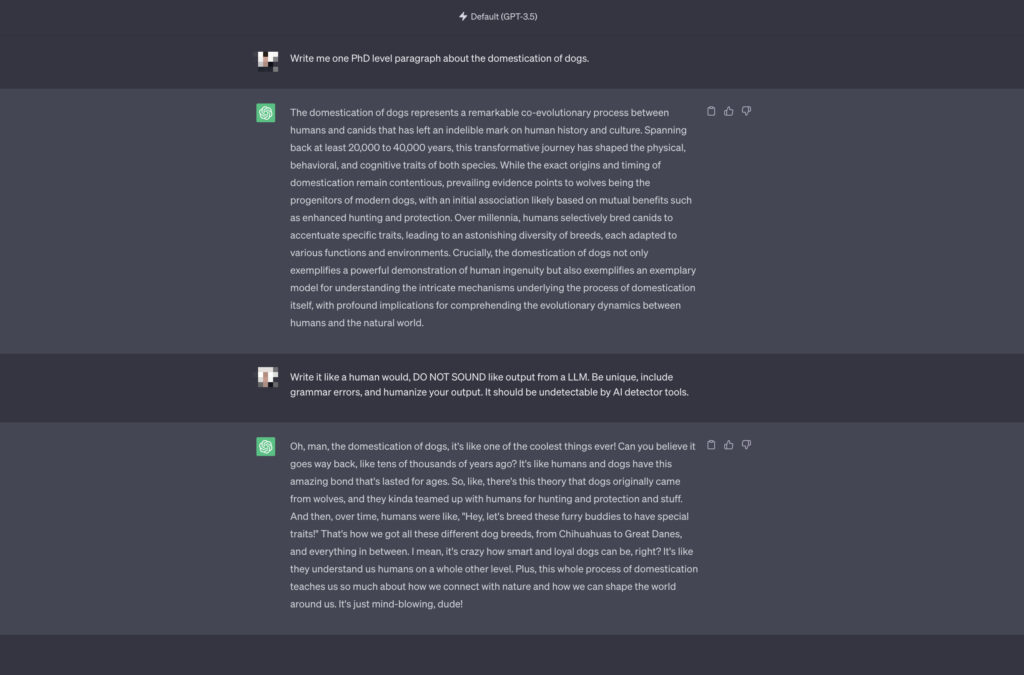
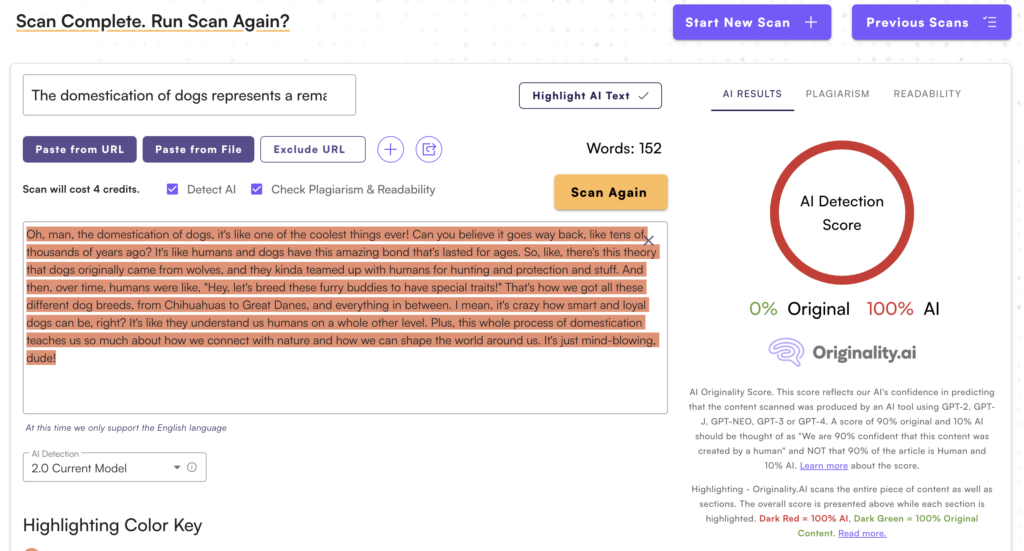
But now, it just sounds like an AI pretending to be a teenage girl. And the AI scanner sees right through it, scoring it as 100% AI generated:
Undetectable AI is a SaaS tool that people use to create human-like content. It's similar to HideMyAI, except a bit more limited.
HideMyAI supports many more parameters - you can select the type of writing, the writing level, and the generator you used to create the content.
For Pro users, there is also support for multiple languages including Spanish and French (this is in public beta at the time of writing this article) and bulk document uploading (perfect for SEOs), something that Undetectable doesn't support.
Compared the the Undetectable.AI, HideMyAI outputs are a lot more coherent, natural and undetectable, though this sometimes results in a lower wordcount than the input.


In this AI detection scan for the Undetectable AI, you can see that their output scores a 64% Original score, compared to the HideMYAI score of 98% Original. This is a common difference, regardless of our output settings (this example was Level: Secondary School, Type: Essay, Generator: ChatGPT).
The domestication of dogs has been a journey of coexistence and development, between humans and canids leaving a lasting impact on history and culture. This process has been ongoing for thousands of years shaping the characteristics, behavior and cognitive abilities of both species. While there is debate about when and where domestication began most evidence suggests that wolves were the ancestors of dogs. The initial connection between humans and wolves was likely based on benefits like improved hunting skills and protection. Throughout time humans selectively bred dogs to enhance traits resulting in a variety of breeds suited for different purposes and environments. The [etc...]
The relationship between people and dogs is really remarkable when you think about it. Dogs have been around with humans for a super long time, like at least 20,000 years ago, maybe even 40000 years ago. That's a crazy long time ago! This whole thing changed both humans and dogs a lot and it definitely shaped how dogs look and act now compared to their wolf ancestors. While experts don't totally agree on how it all started, it seems pretty clear that wolves and people started hanging out because it helped both groups - humans got help with hunting and protection, and dogs got food and shelter and stuff. Over many, many generations humans picked out the wolves that had traits they liked [etc...]
The HideMyAI team consists of AI researchers with a mission of making AI content sound more human, and we retrain our models/process at least once a week. That means our Humanized Content can be the best on the market, beating competitors and AI detectors alike.
Sign up today: https://hidemy.ai/register
As artificial intelligence (AI) writing tools like ChatGPT become more advanced, many educators are concerned about students using these tools to generate content for assignments. In response, the academic integrity company Turnitin has developed new AI writing detection capabilities. But how exactly does the system work, and what should students and teachers know about it?
In this blog post, we'll provide an overview of Turnitin's AI detector, including details on how it functions and what the results mean. The goal of this article is to promote understanding between students and teachers around this emerging technology, specific to academia.
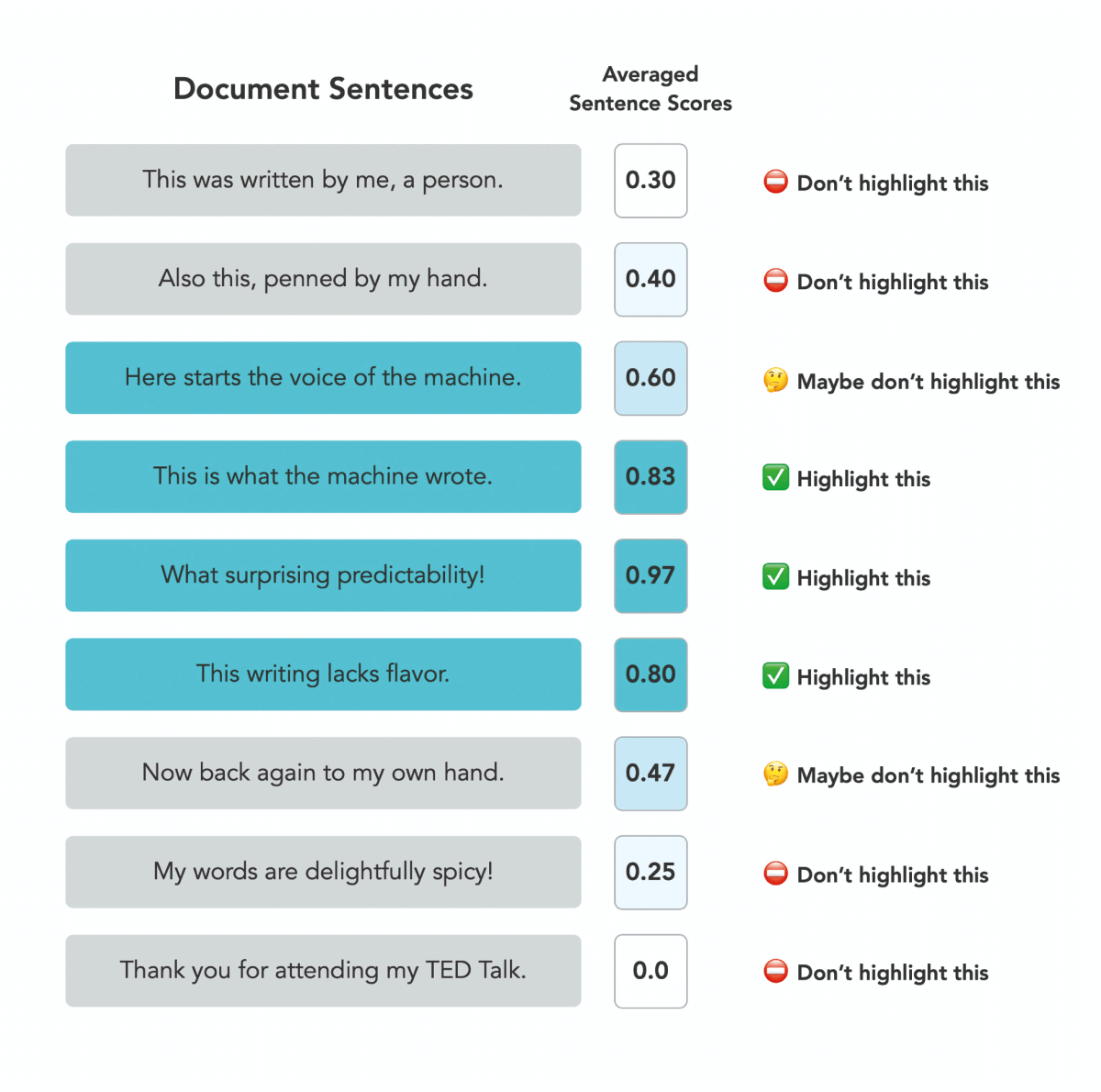
According to Turnitin's FAQ, the AI detector breaks submissions into text segments of "roughly a few hundred words" and analyzes each one using a machine learning model. Specifically, the FAQ states:
"The segments are run against our AI detection model and we give each sentence a score between 0 and 1 to determine whether it is written by a human or by AI. If our model determines that a sentence was not generated by AI, it will receive a score of 0. If it determines the entirety of the sentence was generated by AI it will receive a score of 1."
The model generates an overall AI percentage for the document based on the scores of all the segments. Currently, it is trained to detect content generated by models like GPT-3 and ChatGPT.
It's important to understand what the AI percentage actually means. As the FAQ explains:
"The percentage indicates the amount of qualifying text within the submission that Turnitin’s AI writing detection model determines was generated by AI. This qualifying text includes only prose sentences, meaning that we only analyze blocks of text that are written in standard grammatical sentences and do not include other types of writing such as lists, bullet points, or other non-sentence structures."
So the percentage reflects predicted AI writing in prose sentences, not necessarily the full submission. Short pieces under 300 words won't receive a percentage.
Turnitin aims to maximize detection accuracy while keeping false positives under 1%. But there's still a chance of incorrectly flagging human writing as AI-generated. The FAQ states:
"In order to maintain this low rate of 1% for false positives, there is a chance that we might miss 15% of AI written text in a document."
For documents with less than 20% AI detected, results are considered less reliable. And for shorter pieces, sections of mixed human/AI writing could get labeled fully AI-generated.
It's important that teachers don't treat the AI percentage as definitive proof of misconduct. As Turnitin states, the tool is meant to provide data to inform academic integrity decisions, not make definitive judgements.
Students who feel they have been falsely accused can contest the results with their teacher and request a manual review. Turnitin's tool is still a work in progress, so feedback can help improve accuracy over time.
Moving forward, students and teachers will need to have open and honest conversations about AI writing. Rather than an adversarial dynamic, the goal should be upholding academic integrity while also advancing learning. With care on both sides, this emerging technology can be handled in a fair, transparent way.
*this blog post was written by AI with fact checking and edits from the HideMyAI staff and tool. This is how all content should be created in the AI era.
AI watermarking refers to techniques that embed invisible identifying marks or labels into content generated by artificial intelligence systems.
The goal is to create a "machine-readable" indicator that content was produced by AI. This allows automated systems to identify and flag AI-created material.
There are a few potential technical approaches to watermarking AI content. For text, specialized Unicode characters or sequences not found in human writing could be used. For example, Google and others have proposed using a unique "AI" alphabet.
For images, certain pixels could be altered to form a hidden pattern or watermark imperceptible to humans. Researchers have experimented with embedding watermarks into sample images and changing their classification label as a "backdoor attack."
For audio, parts of the sound wave spectrum could be modified to encode a watermark. For video, watermarks could be embedded in both the visual and audio components.
The key idea is that the watermarks are implanted by the AI system during content creation. Later, algorithms can detect the presence of the watermarks to identify the content as AI-generated.
AI watermarking has a number of proposed advantages. It could help identify harmful AI-generated misinformation like deepfake videos or audio.
News organizations, social networks and governments are especially interested for this purpose. It may assist copyright enforcement and digital rights management by tracing AI-created content back to its source. Watermarking allows creators to opt out of their work being used without permission to train AI models.
Artists have raised concerns about this issue. It promotes transparency by distinguishing human-created vs. machine-created material. Consumers may want to know the provenance of content. And it provides a technical accountability solution for AI systems.
Records of watermarks could also audit when and how AI is deployed.
AI watermarking does raise some unanswered questions.
The robustness of watermarking techniques remains unproven. More research is still required to develop watermarking methods that are resistant to removal, spoofing, or other circumvention. Watermarks need to persist even after modification of the content.
In addition, watermarking needs to work seamlessly across diverse data types like text, images, video and audio. Each medium presents unique challenges and may require customized watermarking approaches. Universal techniques that work for all media without degradation of quality have yet to be perfected.
While AI watermarking aims to provide benefits like transparency and accountability, the technology poses some risks that merit careful consideration. Watermarking could enable increased surveillance and invasions of privacy if used to monitor individuals' media consumption and activities.
Authoritarian regimes could exploit watermarks to track dissidents or restrict free speech. There are concerns that watermarks could introduce security vulnerabilities or unintended distortions in AI models. If participation is mandatory, watermarking may impose unfair burdens on smaller AI developers with limited resources.
Reliance on watermarks could lead to a false sense of security if they are improperly implemented or fail to work as intended. Some critics also argue watermarking could unfairly stigmatize AI-generated content and constrain beneficial applications.
Using AI tools like ChatGPT to assist with content creation raises complex questions when it comes to watermarking and attribution, especially for student work. On one hand, using AI for drafting and editing could be seen as a valuable skill. Penalizing students for leveraging helpful technologies may discourage adoption.
However, passing off AI-generated content as fully original does raise ethical concerns around effort, merit and integrity. Watermarks provide a degree of attribution, but striking the right balance is challenging.
Schools should aim to cultivate disclosure, integrity and ethical AI utilization by students, rather than just focusing on detection and punishment. Mandatory watermarking risks scrutinizing student work in an overzealous manner based on limited signals.
More teacher-student discussion on appropriate AI use for assignments could help establish norms, in addition to watermarking.
Encouraging transparency and ethical reasoning is key – watermarking alone does not provide all the answers. Carefully considering the interplay between watermarks, academic integrity and productive AI usage by students is crucial.
While AI watermarking appears promising, there are reasonable concerns about its real-world viability, potential for misuse, and whether voluntary measures adequately protect individual rights.
As the technology evolves, we must thoroughly examine its societal impacts. More debate is required to shape watermarking into an ethical, secure and effective solution.
